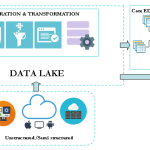
The Enterprise Data Warehouse (EDW) offload is a widespread big data use case. This is certainly because traditional data warehouse and related etl processes are struggling to keep the pace in the big data integration context.
Many organisations are looking to integrate new big data sources that come with the following constraints: volume, velocity and variety (structured, semi-structured and unstructured data). Meanwhile, traditional data warehouse costs are exploding with data volumes and they only excel at serving up structured data at high concurrency and very low latency.
Why not shifting your etl or elt workloads to Hadoop and freeing up data warehouse capacity for faster analytics? Not only It can help your organisation to dramatically reduce costs but It will facilitate agile and iterative data discovery between legacy systems and big data sources.
Apache Spark and Hadoop is a very good combination to offload your etl or elt:
- Spark offers a unified stack which combine seamlessly different type of workloads (batch application, streaming, iterative algorithms, interactive queries…etc.) on the same engine.
- Hadoop offers cheaper storage and processing engine.
Although in the big data context we are expecting to deal with a variety of data sources, the etl processes need to be streamlined to maintain all the agility required to:
- Acquire new data sources
- Test business concepts
- Validate and industrialize
A single framework to integrate all the data sources available is the way to go.
In our previous blog posts (part1, part2), we have outlined in detail the implementation of such framework built with Apache Spark to support these etl processes.
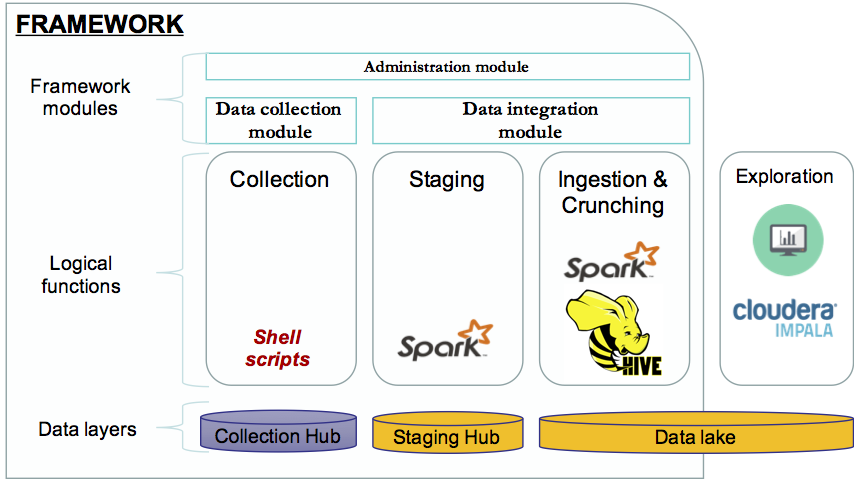
Below is the overall architecture of the framework:
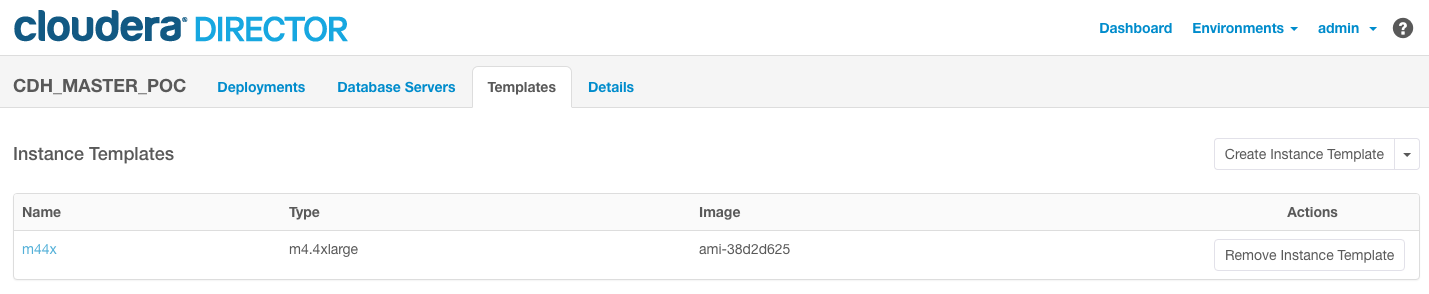
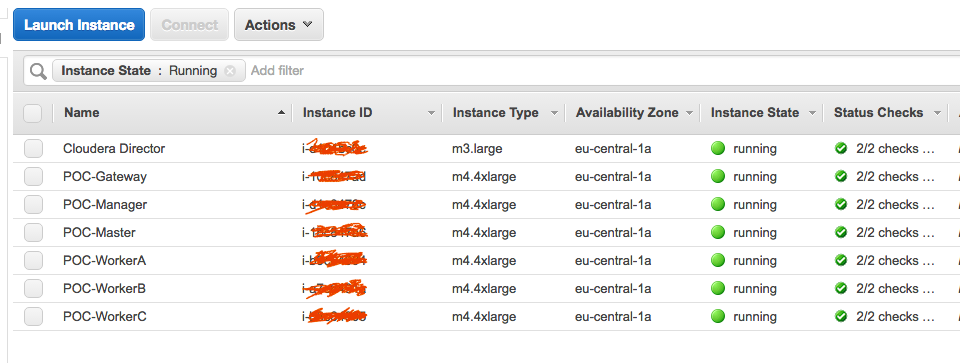
We have created on AWS a CDH (Cloudera Distribution Hadoop) cluster of 5 nodes. We are using Amazon EC2 m4.4xlarge instance type.
Our dataset* contain various information such as:
- Call Detail Records (CDRs) generated by the Telecom Italia cellular network over the Province of Trento.
- Measurements about temperature, precipitation and wind speed/direction taken in 36 Weather Stations.
- Amount of current flowing through the electrical grid of the Trentino province at specific instants.
Data source: https://dandelion.eu/datamine/open-big-data/
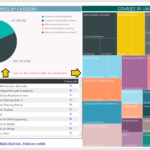
In our example below, we only ingest telecommunication and energy data. It did take approximatively half an hour to collect one month of historical record, store them as parquet files and ingest them in Hive:

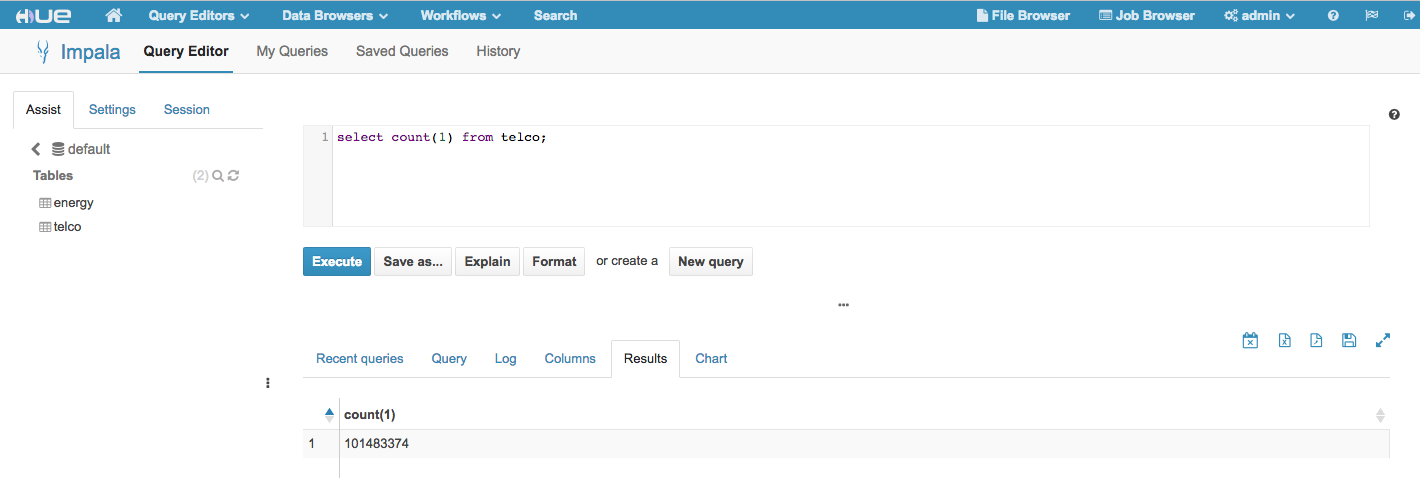
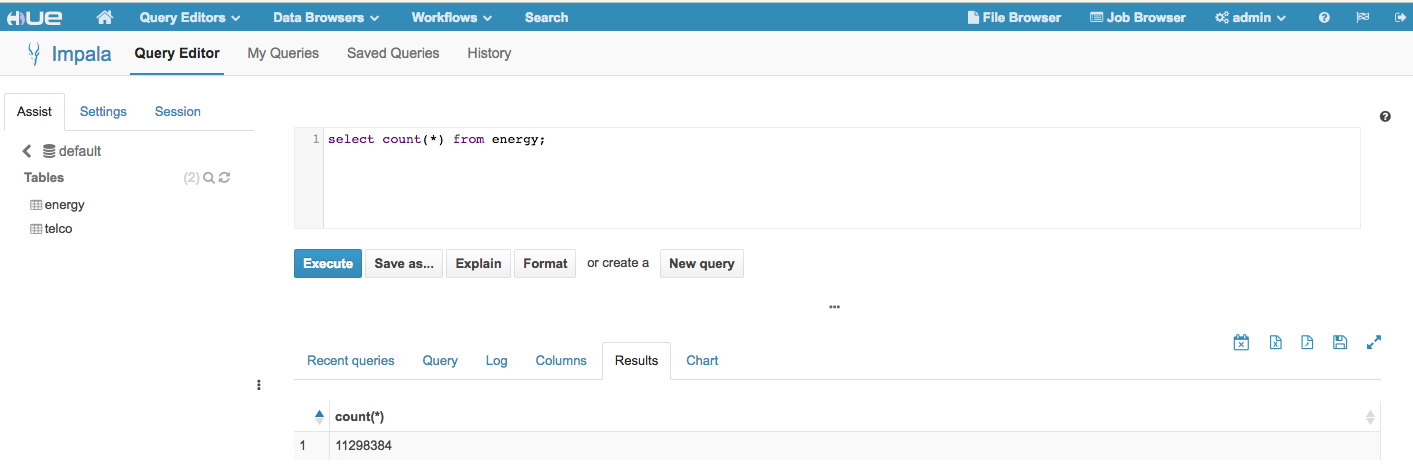
The interactive data exploration with Impala shows good result in term of query response time:

Apache Spark offers a very good foundation for etl offload to Hadoop. A single framework to streamline the etl processes is the best approach. The key benefits of the framework discussed in this use case are:
- Agility & time to market – give the ability to quickly acquire new data sources
- Reusability – data engineers need to focus on data integration without re-writing core functionalities for every new project or proof of concept.
- Accessibility – core etl transformations are written in SQL making therefore this framework accessible to most data engineers.
- Flexibility – each module of the framework can be enhanced independently and everyone will benefit from these evolutions.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.