In our previous blog post, we’ve discussed the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices (smart city data set). We will now explore in detail, the components of this framework.
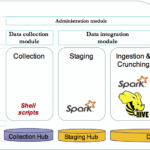
The framework is composed by 2 independents modules and one administration module that contains common functions. The choice has been made to create independents modules, as they achieve very different logical functions:
- Data collection: get the various data sources as they are available and stored the data in hdfs.
- Data integration: apply transformation to the data to extract meaningful information and store the results in hive.
These modules are highlighted below in yellow:
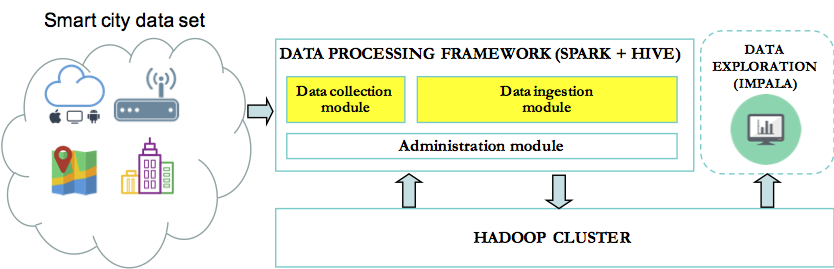
The framework has been designed with flexibility in mind, so that each module can be customized and enhanced without impacting the others.
Administration module
The administration module contains common functions that are not directly related to the data collection and ingestion such as installation scripts, generic scripts to handle log message, global properties files…etc.
Data collection module
This module is designed to collect data from various data sources as they are available and stored them in Hadoop file system. The data sources (smart city data set) to be ingested are described in data catalog which contains each data source properties such as the type (local, aws, api..etc), connection properties..etc.
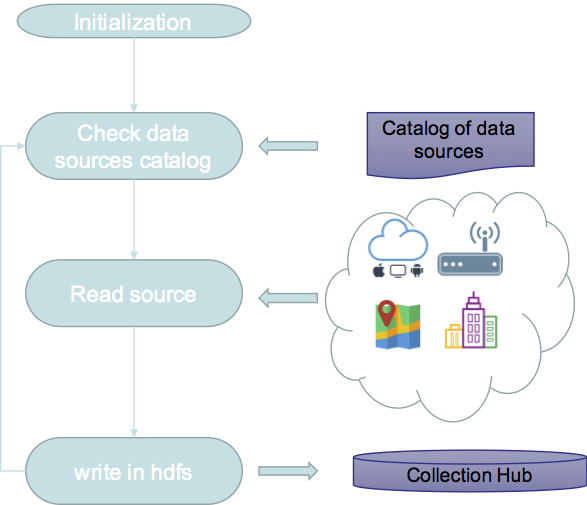
Data integration module
The data ingestion is realized in two steps:
Step1: Collect all data available in the hdfs hub, convert them in parquet and save them in a staging folder. The goal of this step is to build a source agnostic representation of the data. Spark does not really need to know if the data was originally in csv, txt, json…etc. Parquet format has been chosen to enable fast execution of Spark queries.

Step2: The purpose of this function is to use Spark SQL engine to execute pre-defined sql template that contains the transformations to apply to the data. Most of the time, the requirement for the data to be extracted can change. We need to avoid rewriting the entire script, every time that we need to extract some pieces of information for the data consumers. To support this functionality, we rely on two concepts:
- Configuration files that contains the information about the data that we want to compute and where we want to store the results in Hive
- Templates files that contains SQL queries to be executed to apply transformation/extraction

This concept of a framework aims to avoid rewriting new scripts for every new data sources available. Spark has been identified as a good candidate, as it offers the ability to execute various workloads and support multiple type of computations.
The framework has been designed with flexibility in mind. The current two core modules are independent and can be replaced or customized without impacting the whole solution.
In addition, it enables a team of data engineer to easily collaborate on a project using the same core engine. Each member can focus on writing their templates and updating configuration files. Everyone can benefit from evolution to the core modules.
Check our next post to see the framework in action on Amazon Web Services (AWS).
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.