In the previous post, we discussed data warehouse concept and emphasis key aspects such as data consistency, data history, complexity of the data integration process as the number of data sources grows and time to market. The enterprise data warehouse is built for analytical purpose and stored mainly structured data. It gives a competitive advantage to companies by allowing them to leverage their data to make better decisions and predictions.
Sadly, in the digital marketplace it lacks the speed and flexibility needed to fulfill its ultimate goal.
The digital business models have become essentials for companies that are wishing to thrive and stay competitive. By going digital, these companies are gaining interest to the information available beyond the scope of structured data. These are the semi-structured data and unstructured data. Here are some examples: log journal from website activity, social media feeds, video, audio, text document… and so on.
These new types of information are no longer compatible with the enterprise data warehouse requirements. The concept of data lake has then emerged to tackle the increasingly need of agility and accessibility to the information on a timely basis. Its implementation has been highly facilitated by Hadoop based technologies (designed to absorb volume, velocity and variety) and cheaper storage cost.
A data lake is basically a repository that stores large amount of disparate raw data. It doesn’t have the same requirement of data consolidation and standardization as the enterprise data warehouse. It therefore gives more flexibility to collect new heterogeneous data sources. Albeit data lake and data warehouse do not share the same constraints and requirements, one can supplement the other. Indeed, the data lake can act as staging layer for the data warehouse and offload the ETL process, thanks to the ability to process data at lower cost.
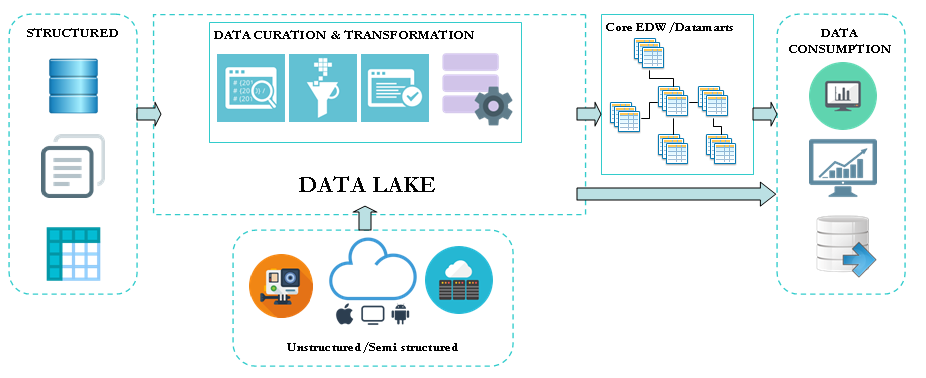
An appealing promise of data lake is to break data silos by offering a repository that enables business intelligence across all the company data. The temptation is therefore to dump any data available in the data lake with the expectation to get back to it in the future. The leap between data lake and data swamp is very easy to make.
Data lake is not just about a repository with disparate raw data. It needs proper data management, governance and security rules. A data lake without a catalog that keeps track of available data and ensures that any information stored can be surfaced is useless. It can jeopardise data analytic effort and become a liability more than an asset.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.