Over the past weeks I was involved in few discussions where it appeared that the difference between enterprise data warehouse and data lake is not crystal clear for some decision makers. Let’s explore in this series of two posts the key differences between these two concepts and how they can be bound together.
The enterprise data warehouse is a central repository built from multiple data sources (operational data, transactional data, external/third-party data…) to enable the organization to leverage their data for a better understanding of the business and to support decision making.
Bill Imon and Ralph Kimball are considered as the fathers of this concept, although they have very different views on its design and implementation.
A data warehouse is oriented for data consumption as opposed to online transaction processing systems. It’s therefore designed for better analytic performance. It’s aimed to be the organization “single version of truth”. Two key aspects of the data warehouse are consistency and data history.
Consistency is guarantee by providing a single view of the information regardless of the data source. For example customer data may come from various data points:
- Sales transactions from different channels (agencies, internet…)
- Invoices
- Shipments
- Sales campaigns
- …
However instead of creating multiple versions of the customer over the different subjects areas, only one common version will be stored.
Data history historical data are kept in order to analyze change over time. This is an important feature of data warehouse.
The enterprise data warehouse is designed for structured data. An integration process is set in place to ensure quality, consistency and integrity of the data loaded.
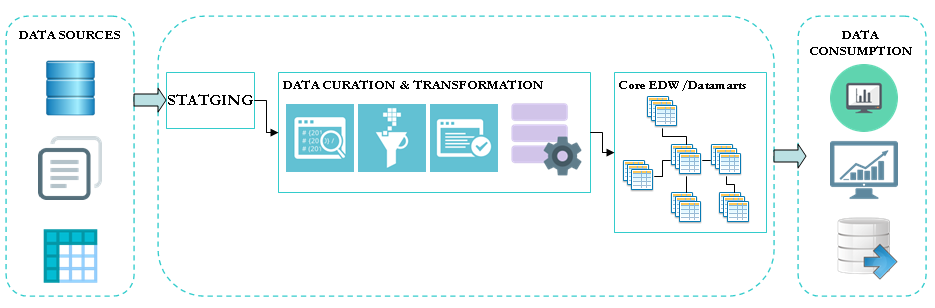
The complexity of this data integration process increases with the number of data sources. For each new data source:
- the impacts on the enterprise data model need to be accessed;
- business analysts need to define the mapping between the source data and target entities in the data model;
- the integration process is developed by a programmer based on the data mapping.
All these steps need to be accomplished before the new information can be available to the data consumers. It can take anywhere between few weeks to few months. It’s mainly depends on how well designed is the data warehouse. It raises a key constraint of data warehouse implementation which is time to market.
The concept of ‘datalab’ has been developed to partially address this constraint. A datalab is a specific layer of the enterprise data warehouse where you can dump new data sources without going through the whole data standardization process. It allows skilled data consumers to run experimentation (proof of concept, data mining…etc) with new sources of information in order to derive value from it, long before that information is made available in the enterprise data warehouse.

To a certain extent, datalabs are the embryonary version of the data lakes. We will discuss further data lakes in the next post.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.