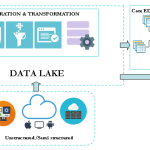
The Enterprise Data Warehouse (EDW) offload is a widespread big data use case. This is certainly because traditional data warehouse and related etl processes are struggling to keep the pace in the big data integration context. Many organisations are looking to integrate new big data sources that come with the following constraints: volume, velocity and […]
SparkSQL
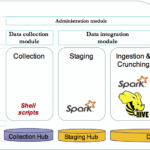
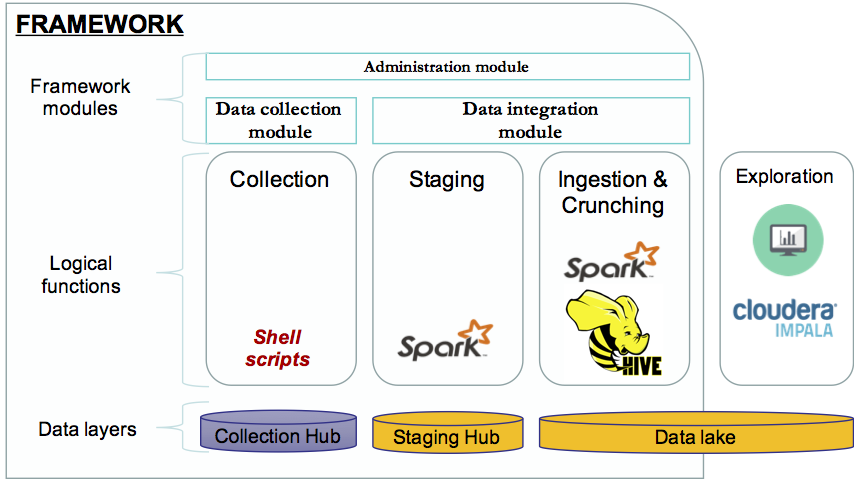
In our previous blog post, we’ve discussed the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices (smart city data set). We will now explore in detail, the components of this framework. The framework is composed by […]

{kind=link}
{kind=link}