It’s widely acknowledged that data scientists spend most of their time on data integration (curation) therefore focusing less on their core activities. Let’s have a look at an appealing tentative to mitigate this effort.
Most companies tend to integrate more and more data sources in their data warehouse over the past years. It has been highly facilitate by the increasing storage capacity of databases and the performance of most database management systems (DBMS).
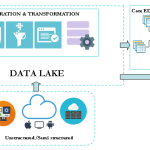
These data sources may represent the same business concepts or information in various ways and some might well be very poor in term of data quality. Therefore, in order to get any valuable insights from the data, it needs first, to be ingested, cleaned and transformed to provide accurate information to the data consumers (either a human or an application). This process of data collection and preparation is known as data integration.
Along with the eager of capturing more information in the databases, various ETL and ELT tools emerge on the market:
- E = Extract
- T = Transform
- L = Load
These tools facilitate the data integration process by providing a set of native components to tackle most commons data integration concerns. They also give the ability to develop your own routine to address your specific data integration need by providing a wide range of libraries.
A big data case is commonly defined by the following three factors: volume, velocity and variety. Big data demand will increase as analytics requirements are getting far more complex than reporting on structured data stored in the enterprise data warehouse. Below are few examples:
- Personalized product offerings based on customer’s behaviors on social network
- Auto insurance pricing based on driver behavior
- Unlock insights from sensor data
- …and so on
Traditional data integration solutions have in common 3 keys concerns in the big data era:
- Predefine data model: You need to know your sources data structures and the mapping between your sources systems and the target model.
- Programmer oriented integration: The integration process is developed by a programmer based on the mapping knowledge. Any change in the source data structure that needs to be factor into the target model will need to be programmed.
- Scalability: The complexity of the data integration process increase with the number of data sources.
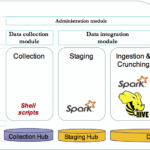
This top-down deterministic approach is not sustainable in big data context due to the variety and velocity of data to be integrated. Hence, some alternatives are being explored. One example is the data tamer system developed at MIT. It aims to be non-programmer oriented relying on machine learning algorithm with human help only when necessary to tackle the data curation and scalability challenge.
As the purpose of this post is not to explore the data tamer architecture into details, let’s focus on 3 keys components:
The overall system will get smarter as more data are ingested. The authors ran their solution against 3 real business cases and achieved good results. You can read more about data tamer here. It worth mentioning that the system has some weaknesses foreseen in future enhancements such as:
- missing entities relationship,
- one possible input format which is CSV,
- limited data integration operations that might require to outsource these operations to a third party solution
This data integration solution surfaces a whole new approach to deal with velocity and variety albeit not yet with volume. It raises some interesting clues to move from human centric to more automated data integration solution. Next generation of data integration solutions will certainly have to deal with this challenge.
Post update : Tamr offers a commercial product of the prototype discussed above. A free version of Tamr catalog is available for download since July 2015.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.