This post is meant to help you making your first step into data processing with Apache Spark using python API.
In the age of Big Data processing, Hadoop map reduce (open source implementation of google map reduce model) has set down the foundation for processing “embarrassingly parallel” operations on distributed machines.
Sadly, it shows programmability limitations and degradation in performance when it comes to more complex applications which implement things such as multi-step algorithms that need to re-use the data or interactive data mining.
Apache Spark tackle these limitations by extending and generalizing the Map Reduce model to offer a unified stack which is:
Spark comes with a set of high level components such as:
Spark API are available in Python, Java, Scala and R. In the next section we will create a spark job using python API to:
- Read a csv file
- Perform aggregation in memory over the data collected
- Persist the result in Hive for interactive data analysis using Impala
Download Cloudera quick start VM and follow the instructions to launch the virtual machine. Cloudera Distribution for Hadoop (CDH) has a rich set of packages available. You can check CDH packaging and tarball information for more details.
The quick start VM* already includes all the packages we need for this use case.
* The guidelines provided in this document have been lately executed on CDH VM 5.12
Create a python script in the home directory (/home/cloudera) named spark_intro.py as follow:
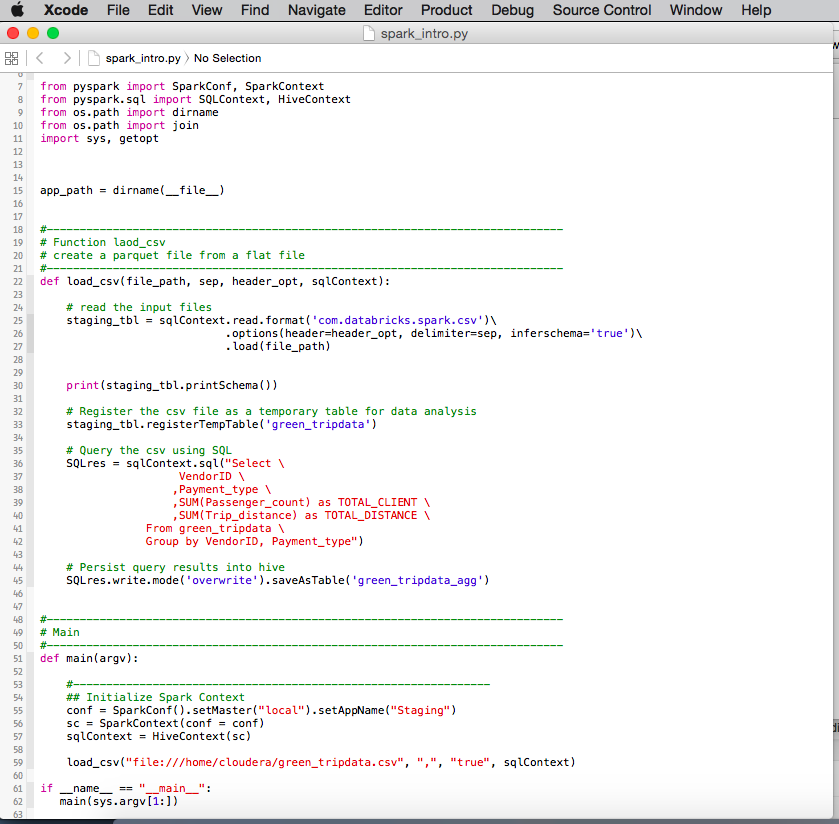
Get the following dataset and rename the csv file as follow: green_tripdata.csv.
Taxi & Limousine commission trip record data : https://s3.amazonaws.com/nyc-tlc/trip+data/green_tripdata_2017-06.csv
Copy this file in the home directory.
The sample code provided above will read the csv file, expose the file structure, aggregate the data and stored the results of the aggregation in Hive for further analysis. Execute the script by running the following command:
[cloudera@quickstart ~]$ spark-submit --packages com.databricks:spark-csv_2.11:1.4.0 spark_intro.py
Once you have successfully executed the spark job, you can explore the resulting hive table with HUE. Open the browser (by default Firefox) and login to HUE (link in bookmarks toolbar): the default username/password is cloudera/cloudera. Check the documentation for further details.
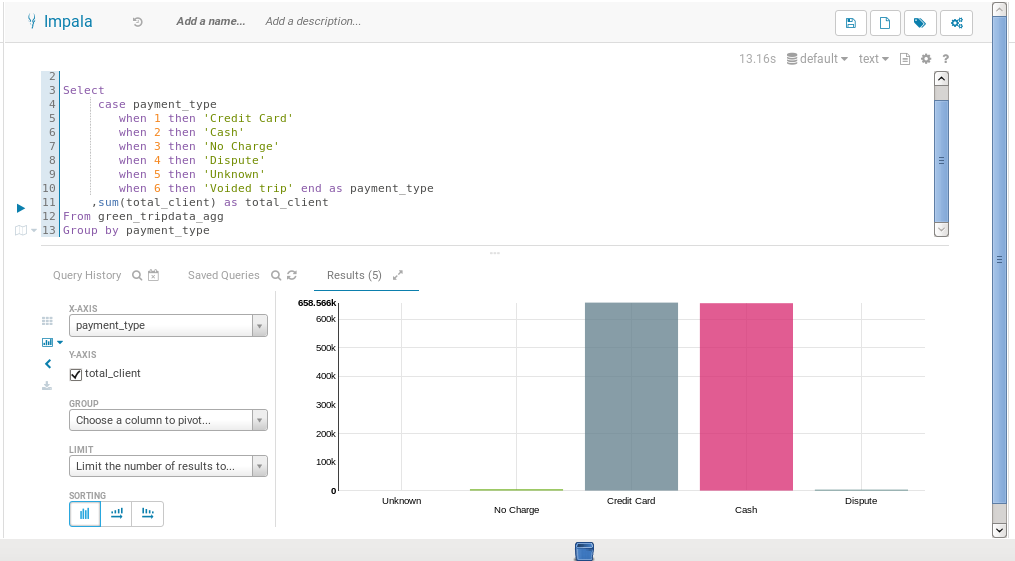
Exemple of query:
Select
case payment_type
when 1 then 'Credit Card'
when 2 then 'Cash'
when 3 then 'No Charge'
when 4 then 'Dispute'
when 5 then 'Unknown'
when 6 then 'Voided trip' end as payment_type
,sum(total_client) as total_client
From green_tripdata_agg
Group by payment_type
You are done! Happy data analysis and exploration with Apache Spark.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.