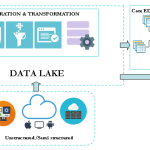
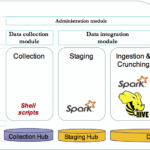
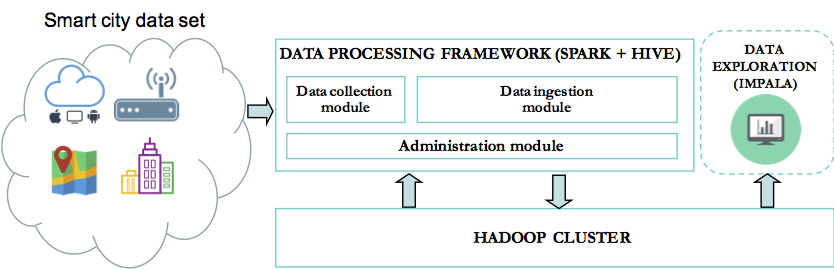
In this series of blog posts, we will outline and explain in detail the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices. The internet of things (IoT) is certainly bringing new challenges for data practitioners. It’s […]
Case Study
This post is meant to help you making your first step into data processing with Apache Spark using python API. In the age of Big Data processing, Hadoop map reduce (open source implementation of google map reduce model) has set down the foundation for processing “embarrassingly parallel” operations on distributed machines. Sadly, it shows programmability limitations and degradation in […]

{kind=link}
{kind=link}