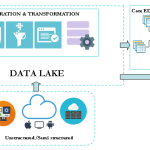
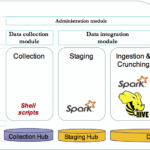
In this series of blog posts, we will outline and explain in detail the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices.
The internet of things (IoT) is certainly bringing new challenges for data practitioners. It’s basically a network of connected objects (the “things”) that can communicate and exchange information. The concept is not new, however there is a significant shift in the list of objects that could be part of this network. Very soon, it will be nearly every object on the planet. There are already few applications emerging around the internet of things, such as smart cities, smart agriculture, domotic & home automation, smart industrial control…etc.
The data* for our case study contain various information such as:
- Call Detail Records (CDRs) generated by the Telecom Italia cellular network over the Province of Trento.
- Measurements about temperature, precipitation and wind speed/direction taken in 36 Weather Stations.
- Amount of current flowing through the electrical grid of the Trentino province at specific instants.
Data source: https://dandelion.eu/datamine/open-big-data/
The primary focus of this framework is not to collect in real-time the data from the devices although it can be extended to support such capability thanks to Spark.
The ultimate goal of the framework approach here is to speed up development effort to ingest new data sources available and reduce time to market for data consumers. It aims to avoid rewriting new scripts for every new data sources available and enables a team of data engineer to easily collaborate on a project using the same core engine.
Framework overview:
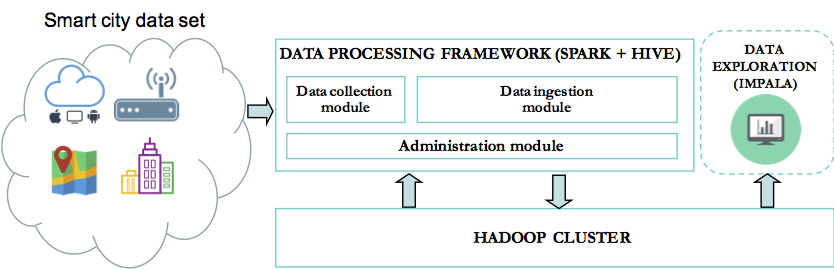
The combination of Spark and Shell scripts enables seamless integration of the data. The data is first stored as parquet files in a staging area. It enables Spark to execute fast SQL queries for processing the data. These SQL queries are pre-defined in templates files that will be executed by the framework engine at the run time. Thus data engineers can focus on writing their transformation to extract meaningful information and let the framework engine process these queries. The results are stored in hive for data consumers. The key benefit of Spark here is to be able to execute various workloads. The framework engine can then be easily extended to support different types of operations in addition to processing SQL templates files.
The framework did perform very well on Amazon Web Services (AWS) with a CDH (Cloudera Distribution Hadoop) cluster of 5 nodes (m4.4xlarge – 64Go 0f memory)
As example, it did ingest in Hive our dataset which include one month of telecommunication Call Detail Records in less than 5min.
Many companies are looking to enrich their conventional data warehouse or data platform with new sources of information that usually come in a variety of format. With the rise of the internet of the things, this concern will certainly become more and more important, as the companies would like to ingest and derive value from these new datasets. They need to do it in an agile way:
- Acquire the data
- Test concepts
- Validate and industrialize
A framework is definitely the way to go. In our next post, we will expose in details the framework components.
© Copyright Certosa Consulting – All Rights Reserved. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Pastel Gbetoho and Certosa Consulting with appropriate and specific direction to the original content.