Big Data topic is deservedly gaining attention not only because of the 5 to 6 numbers figures salary expectation as a data scientist, but also because it is at the heart of strategic endeavours in many companies. It’s therefore not a surprise that many co-workers even without an IT background have heard about these two […]
Articles
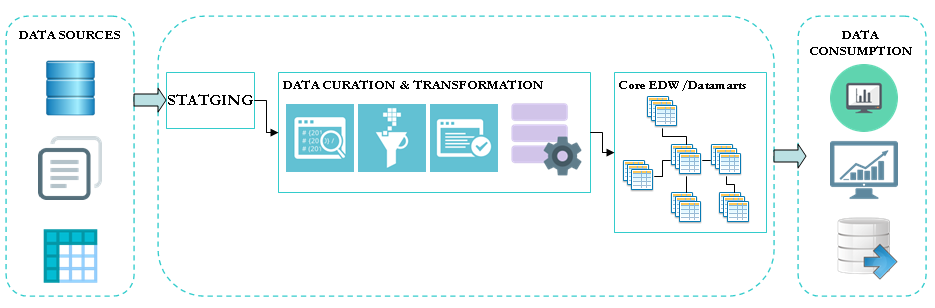
The Enterprise Data Warehouse (EDW) offload is a widespread big data use case. This is certainly because traditional data warehouse and related etl processes are struggling to keep the pace in the big data integration context. Many organisations are looking to integrate new big data sources that come with the following constraints: volume, velocity and […]
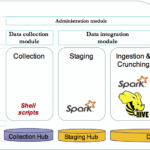
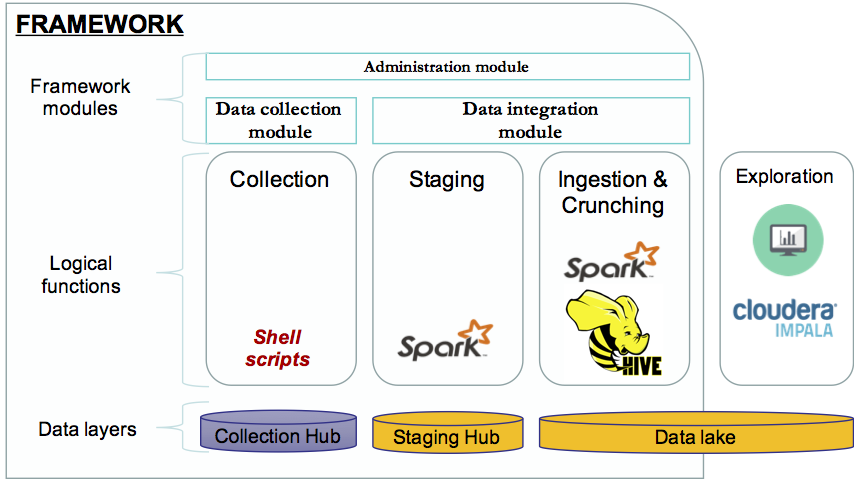
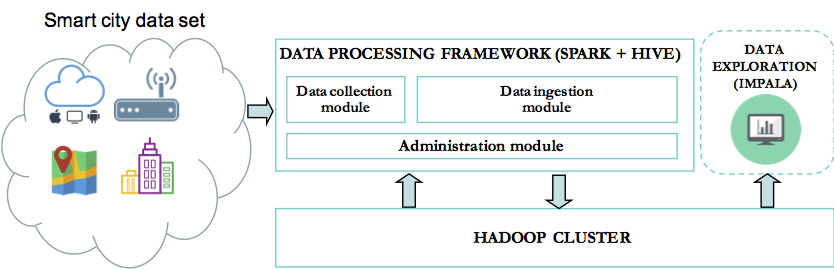
In our previous blog post, we’ve discussed the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices (smart city data set). We will now explore in detail, the components of this framework. The framework is composed by […]
In this series of blog posts, we will outline and explain in detail the implementation of a framework built on top of Spark to enable agile and iterative data discovery between legacy systems and new data sources generated by IoT devices. The internet of things (IoT) is certainly bringing new challenges for data practitioners. It’s […]
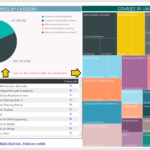
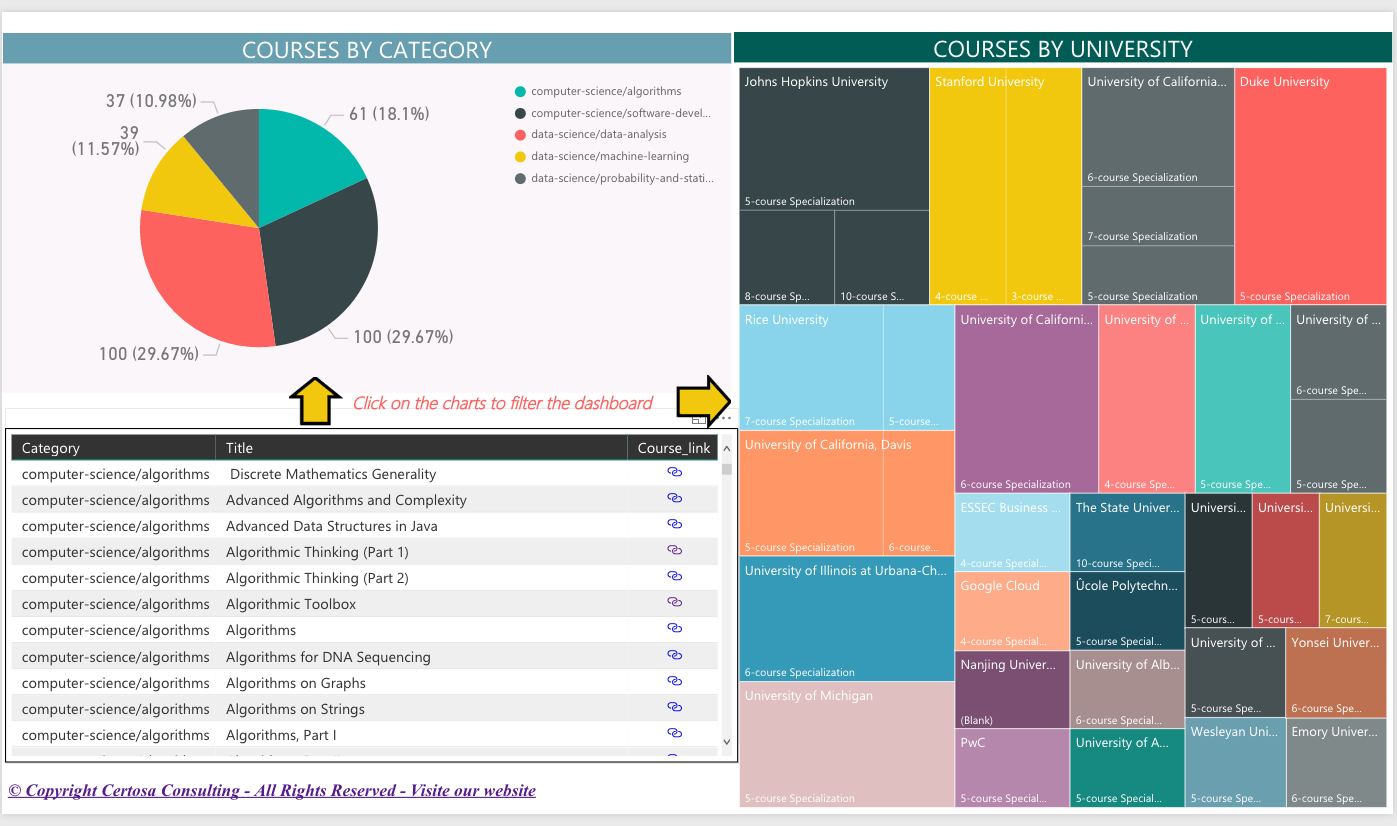
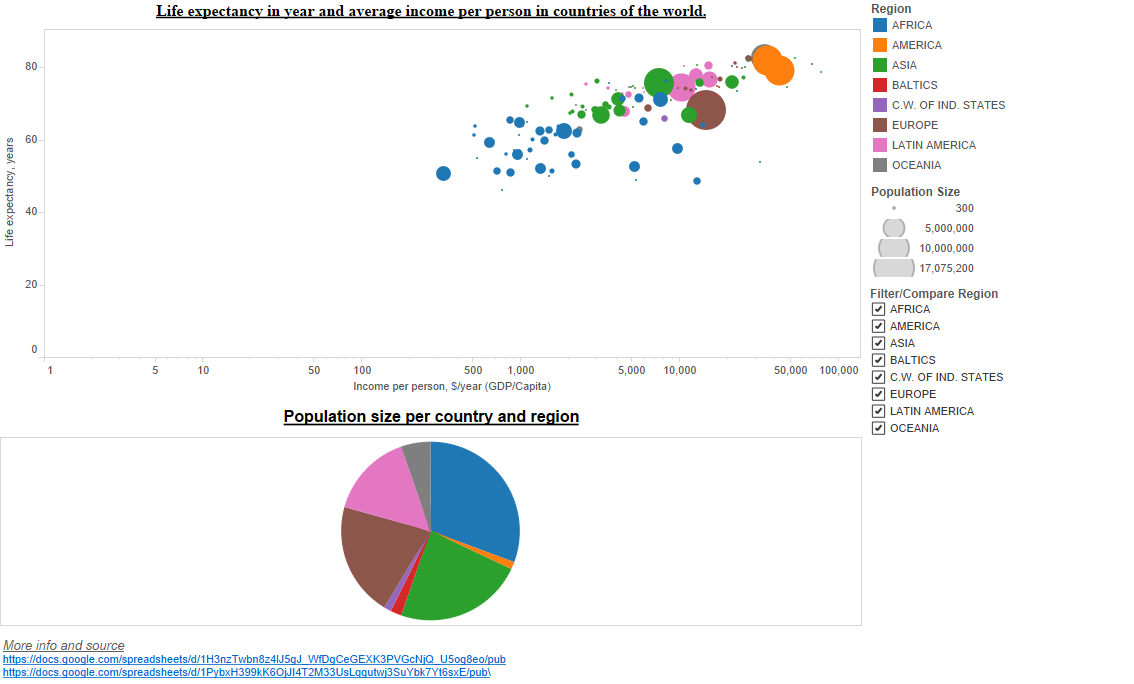
I have explained in a previous post the importance of data visualization and emphasized pitfalls to avoid in order to create effective visualization. In the quest of deriving valuable insights from your data, you will certainly need to visualize and share your findings. Therefore you need to empower the data consumers with the tools to […]
This post is meant to help you making your first step into data processing with Apache Spark using python API. In the age of Big Data processing, Hadoop map reduce (open source implementation of google map reduce model) has set down the foundation for processing “embarrassingly parallel” operations on distributed machines. Sadly, it shows programmability limitations and degradation in […]
In the previous post, we discussed data warehouse concept and emphasis key aspects such as data consistency, data history, complexity of the data integration process as the number of data sources grows and time to market. The enterprise data warehouse is built for analytical purpose and stored mainly structured data. It gives a competitive advantage […]
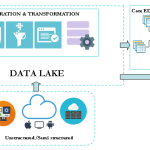
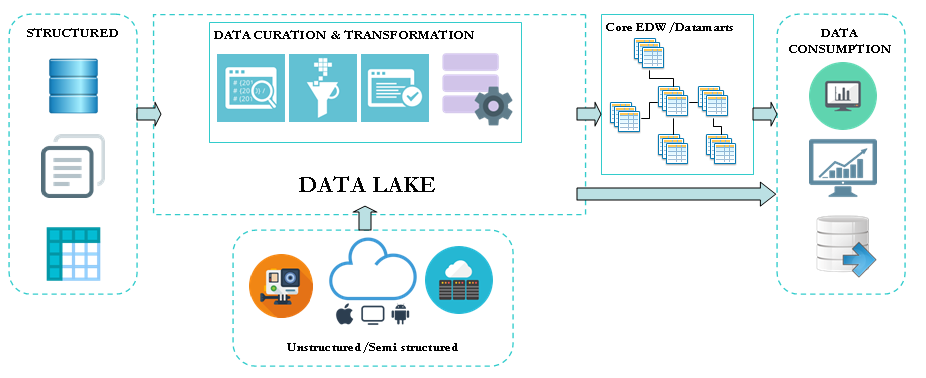
Over the past weeks I was involved in few discussions where it appeared that the difference between enterprise data warehouse and data lake is not crystal clear for some decision makers. Let’s explore in this series of two posts the key differences between these two concepts and how they can be bound together. The enterprise […]
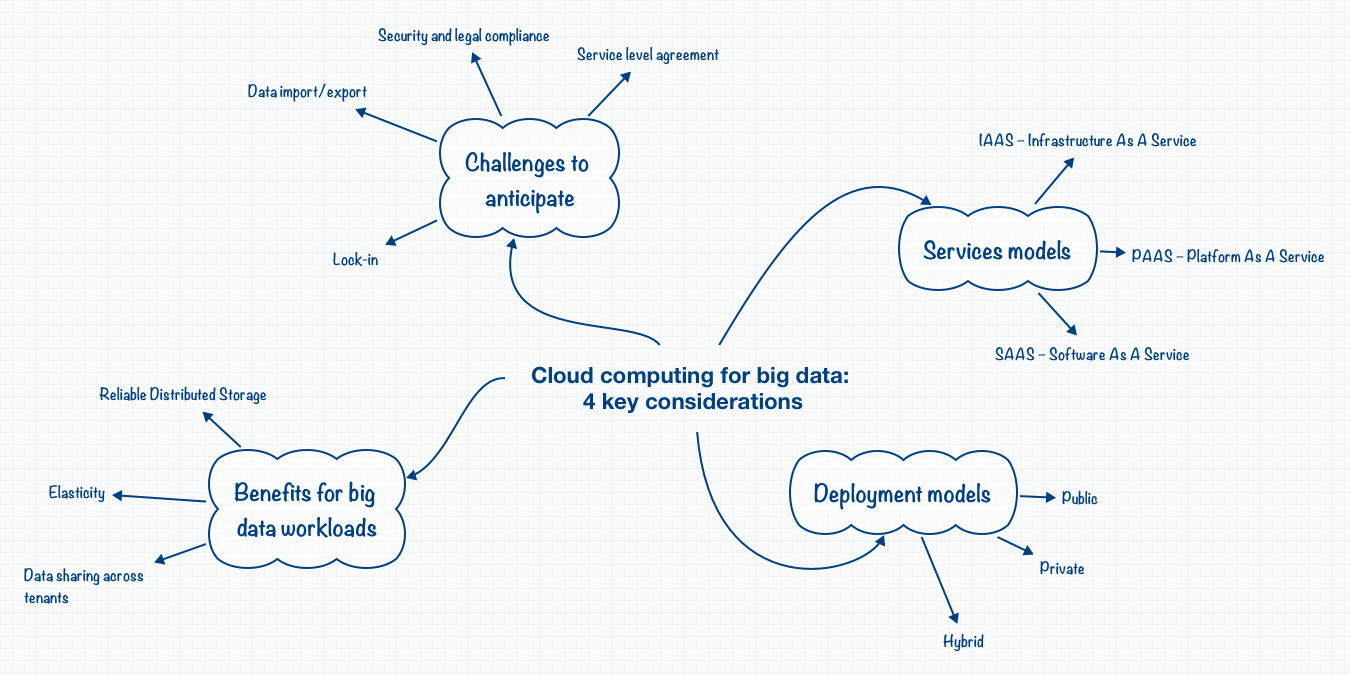
The leap to cloud computing is likely to happen in many companies – if not already the case – considering the flexibility it offers to improve IT efficiency. Cloud computing is simply resources available on demand. It enables companies to purchase large scale IT infrastructures and resources as needed without massive upfront investments. This is […]
Make sure your presentations do not jeopardize the upstream effort and convey the right messages to your audience. Data visualization is a key step in the process of retrieving valuable insights from the data. After doing the hard work (data collection, integration, curation, discovery…etc.) you will have to share your findings. You would certainly need […]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}